Estadística descriptiva vs inferencial: una visión general
Publicado el agosto 30, 2024 por Carolina Guadalupe Cruz Muñoz

Créditos de la imagen destacada: Shafin_Protic – Pixabay
Traductor: Guillermo Adrián Alanis Sánchez – Universidad de Guadalajara, México.
Autor y Artículo original: Carolina Guadalupe Cruz Muñoz– «Descriptive vs inferential statistics: an overview»
Estadística descriptiva
La estadística descriptiva tiene como propósito describir las características de nuestra muestra que hemos seleccionado. Antes de explicar cómo se hace, me gustaría preguntarte: ¿cómo describirías esta imagen?
Cuando describimos algo mencionamos sus características: qué tan grande es, su color, su edad o cómo se ve.
La estadística descriptiva trata de hacer algo similar: se toma una muestra (o grupo) en la que se está interesado, recaba información sobre ella y usa estadísticos de resumen para describir sus propiedades o características. Las características de esta muestra se llaman variables, y algunos ejemplos son el género, la temperatura, la altura, la glucosa sérica, etc. Tal como Alyssa menciona en su post, se pueden clasificar como variables nominales, ordinales o numéricas.

Fuente: leebevan en Freeimages.com
Podemos usar tablas de datos para describir la muestra y las variables que nos interesan. La siguiente tabla es un ejemplo de una tabla de datos, la cual describe el número de estudiantes de diferentes áreas registrados en una clase, así como cuantos de ellos aprobaron la clase. Nótese que no se intentó sacar conclusiones sobre una población mayor. El objetivo es simplemente describir las características de tu muestra.
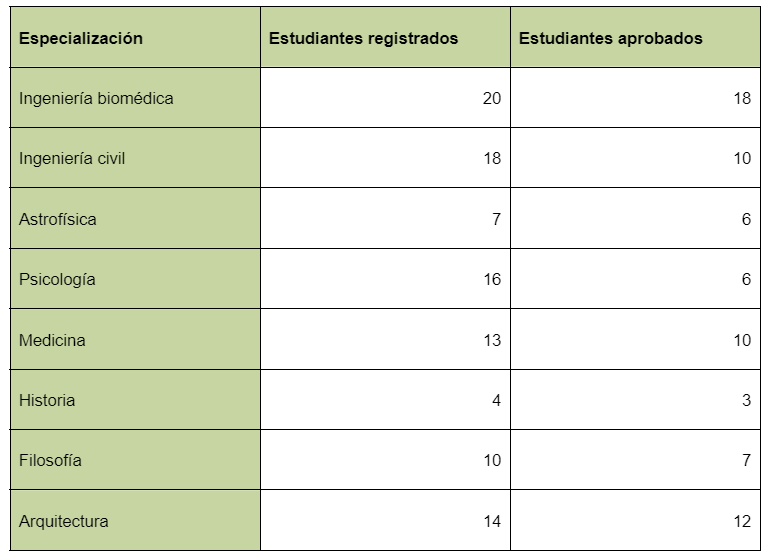
Una vez que los datos se han ordenado en una tabla, los estadísticos descriptivos también hacen uso de gráficos.
Por último, como una forma de sintetizar toda esta información previa, la estadística descriptiva usa medidas de tendencia central (media, mediana o moda) y de variabilidad como rango, cuartiles y desviación estándar. Estas medidas nos pueden dar una visión general de nuestra muestra.
Puedes aprender más sobre estos métodos en tres blogs escritos por Tarik: Medidas de tendencia central, Medidas de variabilidad parte 1 y Medidas de variabilidad parte 2.
Estadística inferencial
Ahora, la información previa puede ayudarnos a describir una muestra, pero en el campo biomédico el objetivo no es solo tratar muestras; queremos incluir, y si es posible, tratar a una población mayor de la cual se obtuvo la muestra. Pero ¿es posible realizar un estudio con miles o incluso millones de individuos? ¡Claro que no! Afortunadamente es donde la inferencia viene al rescate. El objetivo de la estadística inferencial es el de extrapolar los resultados de nuestra muestra a una población mayor. En otras palabras, generaliza la información.
Para poder realizar generalizaciones precisas, nuestra muestra debe reflejar de manera adecuada a una población mayor. Para lograr esto, es importante contar con una muestra obtenida de manera aleatoria.
Observemos tres formas de estadística inferencial:
- Estimación puntual: aplicamos esta para estimar un parámetro usando datos de nuestra muestra. Por ejemplo, podríamos llevar a cabo una encuesta y usar los datos para estimar la proporción de la población que bebe refresco todos los días en cierto país.
- En la estimación del intervalo usamos los intervalos de confianza, de los cuales quizás ya hayas oído hablar. Puedes leer más sobre ellos en este blog de Jessica. En pocas palabras, la estimación del intervalo consiste en estimar un parámetro desconocido usando un rango de valores de nuestra muestra. Por ejemplo, “entre 85-90% de pacientes con una neoplasia (crecimiento celular anormal) relacionada a VPH son mujeres al nacer (Intervalo de confianza de 95%). Esto significa que, si realizamos una encuesta/experimento para comparar el sexo asignado al nacer en aquellos con este tipo de neoplasia, el 95% de las veces esperaríamos que el 85-90% de la muestra fuera del sexo femenino. (Datos no reales para ejemplificar el concepto).
- Prueba de hipótesis: es cuando usamos datos de nuestra muestra para probar una afirmación (o hipótesis) sobre una población mayor y sacar conclusiones sobre esta población con base en los resultados. Por ejemplo, en un estudio donde se compara un tratamiento nuevo con el tratamiento estándar, podemos sacar conclusiones sobre su eficacia y seguridad. Puedes leer más en este blog escrito por Ashline.
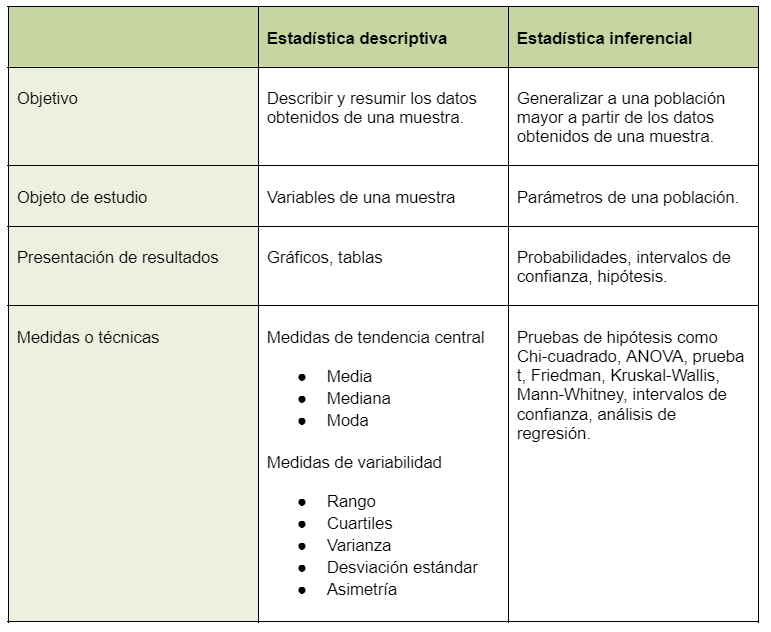
En resumen, aquí está una tabla que presenta las principales diferencias entre estadística descriptiva e inferencial y algunas preguntas para poner a prueba tu conocimiento.
Preguntas:
Determina si los siguientes enunciados se obtuvieron por medio de estadística descriptiva o inferencial. (n.b. estos enunciados fueron inventados).
- Analizamos las calificaciones finales de la especialización de Ingeniería Biomédica en la Universidad N. Los resultados mostraron que, en promedio, los estudiantes de este grupo obtuvieron una calificación final de 78 en Matemáticas y de 97 en Bioética.
- Observamos las calificaciones de mitad de ciclo de la Universidad N. De esta muestra, pudimos estimar que la proporción de estudiantes de licenciatura que obtendrían una calificación final de 75 o mayor es de entre 62% y 79% (intervalo de confianza de 95%).
- Analizamos las calificaciones finales de Matemáticas 101 de los estudiantes de especialización en Matemáticas, y lo que encontramos fue bastante interesante: el rango de sus calificaciones fue 67, 100 siendo la calificación más alta y 33 la más baja.
¡Respuestas al final del blog!
Referencias
- Daniel W. W. (1995). Biostatistics : a foundation for analysis in the health sciences (Sixh). JohnWiley & Sons.
- Gerstman B. B. (2015). Basic biostatistics : statistics for public health practice (Second). Jones & Bartlett Learning.
- Hossain M. & Zubir I. (2021). Making sense of medical statistics : a bite sized visual guide. Cambridge University Press.
- Montanero Fernández, Jesús; Minuesa Abril, Carmen (2018). Estadística básica para las ciencias de la salud. Extremadura (España): Universidad de Extremadura.
- University of Florida. Biostatistics Open Learning Textbook. (2023). Unit 4A: Introduction to Statistical Inference. Retrieved 01 August 2023, from https://bolt.mph.ufl.edu/60506052/unit-4/


